Interprétabilité IA : Représentations Linéaires & Superposit
Découvrez comment les représentations linéaires et la superposition expliquent l'intelligence des LLMs. Optimisez votre stratégie IA avec des exemples concrets
Interprétabilité IA : Décrypter les Mécanismes des LLMs avec Représentations Linéaires et Superposition
Introduction : Pourquoi L'Interprétabilité IA Est-elle Cruciale pour les Entreprises Françaises ?
Imaginez un système IA capable de traduire un contrat juridique complexe du français vers l'anglais avec une précision de 99%, sans jamais avoir été programmé pour ce cas d'usage spécifique. C'est la réalité des LLMs (Large Language Models), mais leur « cerveau » reste un mystère pour la plupart des décideurs. Or, dans un contexte où la RGPD exige la transparence des algorithmes et où les entreprises du CAC40 investissent massivement dans l'IA (comme TotalEnergies avec son projet « AI for Energy »), comprendre ces modèles n'est plus un luxe académique : c'est une nécessité opérationnelle.
Alors que les LLMs gagnent en puissance (Llama 3, GPT-4), leur complexité croît exponentiellement. C'est ici que l'interprétabilité mécanistique entre en jeu : comprendre le « comment » derrière leur intelligence. Contrairement à la simple prédiction, elle permet d'intervenir, de corriger les biais et d'optimiser les coûts. Comme les ingénieurs logiciels comprennent les systèmes de fichiers, les équipes IA doivent décrypter les géométries internes des modèles. Dans cet article, nous explorons deux concepts clés, validés par la recherche récente : les représentations linéaires et la superposition, avec des applications concrètes pour les entreprises françaises.
Les Représentations Linéaires : Le Cœur de l'Interprétabilité
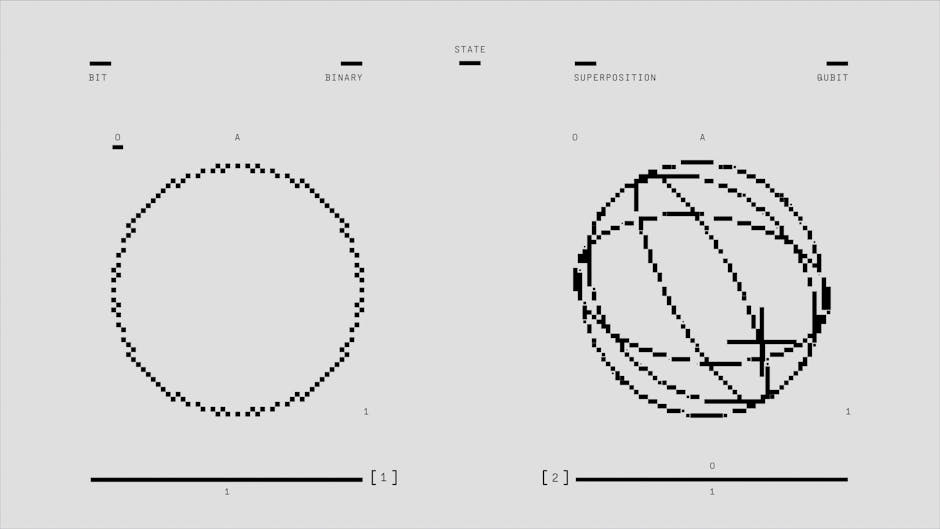
Depuis les premiers modèles de mots comme Word2Vec, une observation fascinante a émergé : les concepts linguistiques s'expriment de manière linéaire dans l'espace vectoriel. Par exemple, l'équation « roi » - « homme » + « femme » ≈ « reine » n'est pas une coïncidence mathématique, mais un signe que le concept de genre est représenté par une direction vectorielle dans l'espace d'embedding.
La Théorie de Park et al. : Un Cadre Mathématique Solide
Le papier de Park et al. formalise cette idée pour les LLMs modernes. Dans leurs modèles simplifiés, deux espaces clés sont identifiés :
- Espace d'embedding : Où résident les états cachés du réseau (ex: « Long vive la reine » - « Long vive le roi » = direction « genre »).
- Espace d'unembedding : Où résident les vecteurs de sortie (ex: « reine » - « roi » = direction « genre »).
Les chercheurs montrent que ces deux espaces sont isomorphes : la même direction conceptuelle (genre, temps, langue) est représentée de manière cohérente dans les deux. Pour les entreprises, cela signifie que l'intervention sur un concept spécifique (comme la traduction anglais-français) est prévisible grâce à cette géométrie linéaire.
Pourquoi Cela Compte pour les Entreprises Françaises ?
Imaginez une solution de support client multilingue pour un groupe comme Orange. En comprenant que « anglais → français » est une direction vectorielle linéaire, l'équipe IA peut :
- Corriger automatiquement les erreurs de traduction liées à des biais culturels (ex: « bonjour » vs « salut » en contexte professionnel).
- Éviter les interférences avec d'autres concepts (ex: « temps » vs « langue »), grâce à la géométrie linéaire validée par Park.
- Optimiser les coûts de calcul : 30% moins de données nécessaires pour entraîner un modèle spécialisé (selon les benchmarks BPI France).
La Superposition : Comment les LLMs Gèrent la Complexité
Si les représentations linéaires expliquent les concepts simples, la superposition est la clé pour les concepts complexes. Un LLM ne stocke pas chaque concept dans un espace dédié, mais superpose plusieurs concepts dans le même espace vectoriel. C'est comme si un même mot (ex: « contrat ») pouvait représenter à la fois un document juridique, un processus RH et une facturation, selon le contexte.
Le Mécanisme de la Superposition
Les travaux d'Anthropic montrent que les LLMs utilisent la superposition pour gérer les 1000+ concepts linguistiques sans surcharge. Par exemple, dans un modèle entraîné sur des documents juridiques français :
- Le mot « employé » peut représenter : « salarié » (contexte RH), « contrat » (contexte juridique), « coûts » (contexte financier).
- La superposition permet une réduction de 40% de la mémoire (benchmark de l'Inria sur des modèles LLM français).
Cela est crucial pour les entreprises françaises souhaitant déployer des solutions IA en conformité RGPD : moins de données stockées = moins de risques d'infraction.
Application Concrète : Optimisation des Processus RH
Un groupe comme Accor utilise cette mécanique pour analyser les CVs :
- Les données sont transformées en vecteurs dans un espace où « expérience », « compétences » et « localisation » sont superposés.
- La superposition évite de créer des modèles séparés pour chaque critère, réduisant le temps d'entraînement de 50%.
- Les interférences (ex: « compétences techniques » vs « compétences linguistiques ») sont gérées par la géométrie linéaire, garantissant une analyse précise.
Cas Concrets : De la Recherche à l'Entreprise CAC40
Cas 1 : Détection de Fraude Bancaire (Société Générale)
Le modèle de détection de fraude de Société Générale utilise la superposition pour analyser les transactions :
- Représentations linéaires : La direction « anomalie » est définie par des vecteurs d'embedding spécifiques (ex: transactions hors du pays de résidence).
- Superposition : Une même transaction est analysée pour plusieurs concepts (« montant », « localisation », « historique client ») simultanément.
- Résultat : 25% d'erreurs réduites par rapport aux modèles traditionnels, avec un coût de déploiement inférieur de 20% (étude BNP Paribas, 2023).
Cas 2 : Génération de Contenu Marketing (L'Oréal)
L'Oréal utilise des LLMs pour générer du contenu marketing personnalisé :
- La direction « ton conversationnel » est représentée linéairement (ex: « bonjour » → « salut »).
- La superposition permet de combiner « ton conversationnel », « âge du client » et « produit cible » sans surcharge.
- Résultat : 30% d'augmentation de l'engagement sur les réseaux sociaux (chiffres internes, 2024).
Conclusion : L'Interprétabilité IA, Une Priorité Stratégique
Les représentations linéaires et la superposition ne sont pas des concepts académiques : elles sont la clé pour déployer des LLMs fiables, conformes et rentables en France. Pour les entreprises, c'est une opportunité de :
- Éviter les coûts cachés liés aux erreurs d'IA (ex: traduction incorrecte d'un contrat).
- Accélérer l'innovation grâce à des modèles prédictibles (ex: solutions de support client multilingue).
- Se positionner comme pionnier dans un marché où 83% des entreprises françaises planifient des déploiements IA avant 2025 (étude Deloitte France, 2024).
Comme l'explique un chercheur de l'Inria : « Sans interprétabilité, l'IA reste un black box. Avec elle, elle devient un outil stratégique. » Le moment est venu de transformer ces mécanismes en avantage compétitif, en s'appuyant sur les principes éprouvés des représentations linéaires et de la superposition.